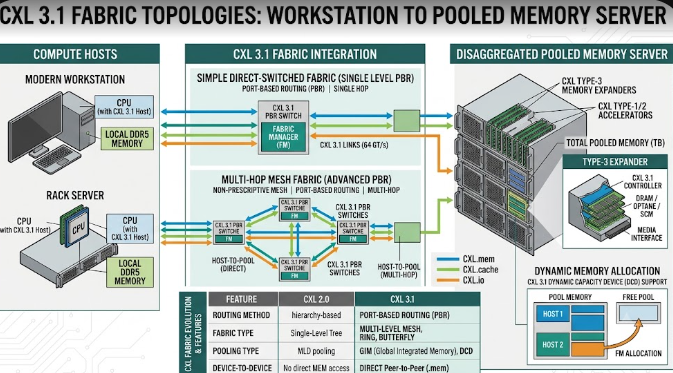
Enterprise IT professionals and structural engineers constantly need more computing power. To meet this demand, technology companies have introduced CXL 3.1 Fabric Topologies. Consequently, modern workstations can now handle massive data loads better than ever before. CXL stands for Compute Express Link. In essence, it is a high-speed connection that changes how computer parts talk to each other. Furthermore, this new specification allows computers to share memory over a network. Therefore, data analysts and engineers can run heavy simulations without slowing down their machines. In this article, we will explore how this technology works and why it matters for your heavy-duty computing tasks.
Direct Core-to-Memory Links in CXL 3.1 Fabric Topologies
First, let us look at direct core-to-memory links. The Compute Express Link (CXL) 3.1 specification runs over the fast PCIe Gen 6 infrastructure. Basically, it creates a superhighway between the computer’s processor (CPU) and the memory (RAM).
Traditionally, a CPU could only use the RAM plugged directly into its own motherboard. However, CXL 3.1 Fabric Topologies change this old setup entirely. Now, a CPU can access external RAM pools over a fast network. Specifically, it does this with near-zero latency overhead. Latency simply means delay. Because the delay is so tiny, the CPU treats this external memory exactly like its own internal memory. For example, if a civil engineer loads a massive bridge design, the computer pulls memory from the external pool instantly.
Dynamic Resource Allocation for Heavy Tasks
Next, we must discuss dynamic resource allocation. This feature is a game-changer for extreme workstation planners. Modern workflows require a flexible architectural specification. With CXL 3.1 Fabric Topologies, a master workstation can dynamically borrow blocks of memory from a centralized server fabric.
Imagine you are running massive structural simulations or complex 3D rendering tasks for a skyscraper. Suddenly, your workstation runs out of memory. Previously, the computer would crash or slow down drastically. Instead, the system automatically borrows extra memory from the centralized pool just for that specific task. Once the simulation finishes, the workstation returns the memory to the server. Consequently, other computers on the network can use that same memory block later. This process saves money and boosts overall efficiency.
The Cache Coherency Metric in CXL 3.1 Fabric Topologies
Finally, we must understand the cache coherency metric. Cache coherency remains the foundational specification of CXL technology. Without it, sharing memory would cause massive data corruption across the server.
When multiple computer parts share the same memory, they need to know what the others are doing. For instance, suppose a graphics card (GPU) modifies data in the pooled memory during a 3D rendering job. Thanks to CXL 3.1 Fabric Topologies, the main CPU instantly recognizes this change. Therefore, the CPU will not accidentally use the old, outdated data. The system constantly checks and updates all data across the network. As a result, engineers enjoy smooth, error-free simulations every single time.
In conclusion, this technology prepares your IT infrastructure for the future of civil engineering. If you want to learn more about the technical side of the Compute Express Link standard, please visit the official CXL Consortium website for further reading.
References
- Compute Express Link Consortium. (2024). CXL 3.1 Specification.
- PCI-SIG. (2024). PCI Express (PCIe) 6.0 Specification.